Researcher: Search Web and Write Reports
Introduction
Background
In MetaGPT, the role of a researcher allows users to conduct research by summarizing information gathered from the internet based on user queries. This document will cover the researcher role from aspects such as design philosophy, code implementation, usage examples, etc.
Objective
Through this document, you can learn how to use the MetaGPT researcher role to search the internet and summarize reports. Additionally, you can leverage MetaGPT's networking capabilities to develop new intelligent agents.
Source Code
Design Overview
Design Philosophy
Before developing the Researcher role in MetaGPT, it's essential to consider how one would conduct research on the internet. Generally, the process involves the following steps:
Analyze the research question and break it down into several sub-questions suitable for searching with a search engine. Use a search engine to search for sub-questions, review the search results with titles, original URLs, abstracts, etc., and determine the relevance and reliability of each result. Decide whether to further browse the web using the provided URLs. Click on the web pages that need further exploration, assess whether the content is helpful for the research question, extract relevant information, and record it. Aggregate all recorded relevant information and write a report addressing the research question. Therefore, we aim to simulate the above research process using GPT. The overall steps are as follows:
User inputs the research question. Researcher generates a set of research questions using GPT, forming an objective opinion on any given task. Upon receiving the decomposed questions from GPT, the researcher, for each research question, searches through a search engine to obtain initial search results. Retrieve web page content using a browser for the URLs and summarize the web page content. Consolidate all summarized content and track their sources. Finally, instruct GPT to generate the final research report based on the consolidated content. The following is a flowchart illustrating the Researcher role architecture:
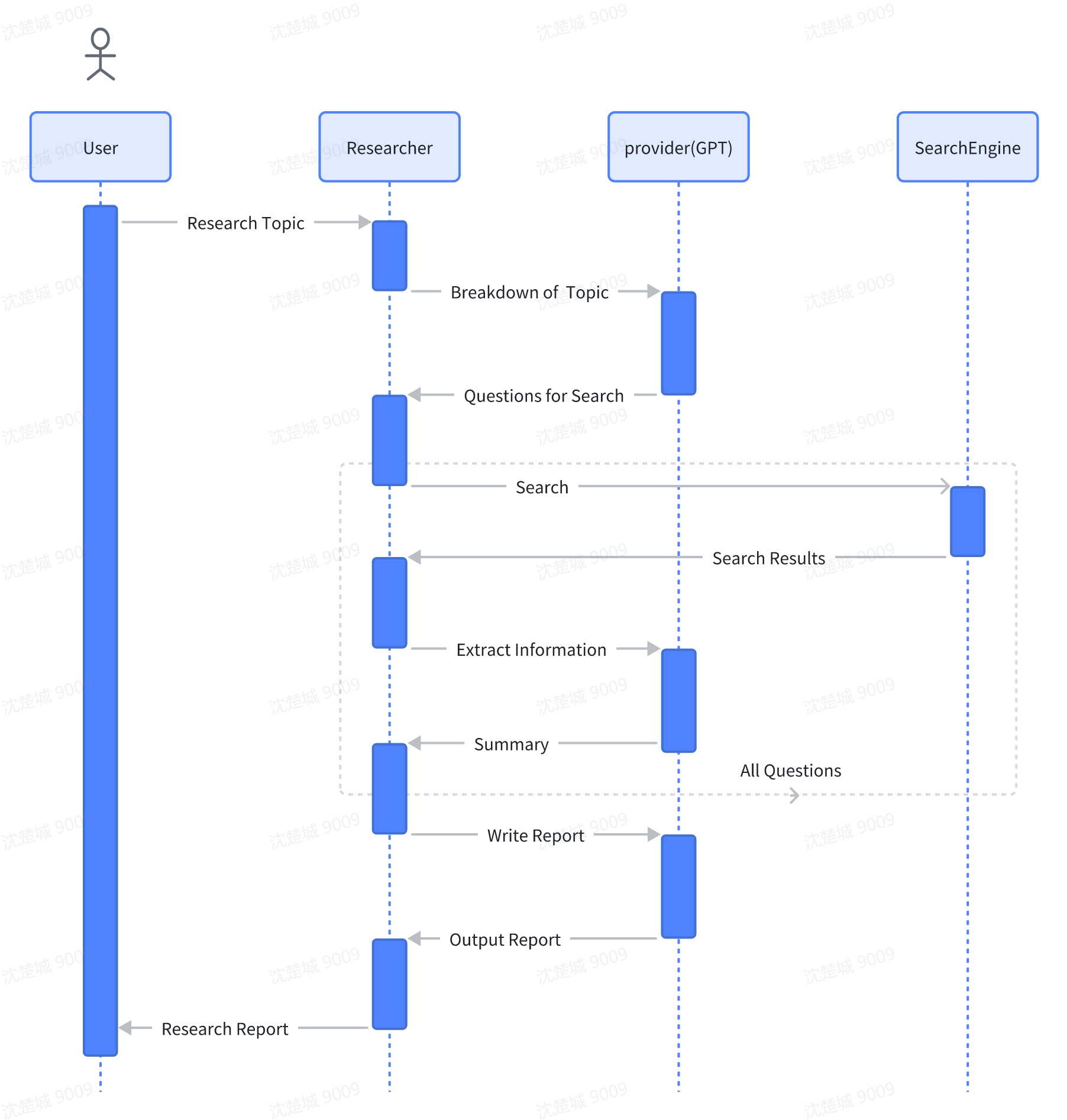
Based on this process, we can abstract three Actions and define a Role as follows:
| Name | Class | Description |
|---|---|---|
| CollectLinks | Action | Collect links from a search engine |
| WebBrowseAndSummarize | Action | Explore the web and provide summaries of articles and webpages |
| ConductResearch | Action | Conduct research and generate a research report |
| Researcher | Role | Search Web and Write Reports |
Action Definitions
CollectLinks
The CollectLinks Action is used to search the internet for relevant questions and retrieve a list of URL addresses. Since user-input questions may not be directly suitable for search engine queries, the CollectLinks Action first breaks down the user's question into multiple sub-questions suitable for search. It then uses a search engine for this purpose. The implementation utilizes the SearchEngine in the tools module, supporting searches through serpapi/google/serper/ddg. The implementation details can be found in metagpt/actions/research.py, and the following provides a basic explanation of the CollectLinks.run method:
class CollectLinks(Action):
async def run(
self,
topic: str,
decomposition_nums: int = 4,
url_per_query: int = 4,
system_text: str | None = None,
) -> dict[str, list[str]]:
"""Run the action to collect links.
Args:
topic: The research topic.
decomposition_nums: The number of search questions to generate.
url_per_query: The number of URLs to collect per search question.
system_text: The system text.
Returns:
A dictionary containing the search questions as keys and the collected URLs as values.
"""
system_text = system_text if system_text else RESEARCH_TOPIC_SYSTEM.format(topic=topic)
# Decompose the research question into multiple sub-problems
keywords = await self._aask(SEARCH_TOPIC_PROMPT, [system_text])
try:
keywords = OutputParser.extract_struct(keywords, list)
keywords = parse_obj_as(list[str], keywords)
except Exception as e:
logger.exception(f"fail to get keywords related to the research topic \"{topic}\" for {e}")
keywords = [topic]
# Search the sub-problems using the search engine
results = await asyncio.gather(*(self.search_engine.run(i, as_string=False) for i in keywords))
# Browse through the search engine results and filter out those relevant to the research question
def gen_msg():
while True:
search_results = "\n".join(f"#### Keyword: {i}\n Search Result: {j}\n" for (i, j) in zip(keywords, results))
prompt = SUMMARIZE_SEARCH_PROMPT.format(decomposition_nums=decomposition_nums, search_results=search_results)
yield prompt
remove = max(results, key=len)
remove.pop()
if len(remove) == 0:
break
prompt = reduce_message_length(gen_msg(), self.llm.model, system_text, CONFIG.max_tokens_rsp)
logger.debug(prompt)
queries = await self._aask(prompt, [system_text])
try:
queries = OutputParser.extract_struct(queries, list)
queries = parse_obj_as(list[str], queries)
except Exception as e:
logger.exception(f"fail to break down the research question due to {e}")
queries = keywords
ret = {}
# Sort and take the TopK URLs from the search results
for query in queries:
ret[query] = await self._search_and_rank_urls(topic, query, url_per_query)
return retclass CollectLinks(Action):
async def run(
self,
topic: str,
decomposition_nums: int = 4,
url_per_query: int = 4,
system_text: str | None = None,
) -> dict[str, list[str]]:
"""Run the action to collect links.
Args:
topic: The research topic.
decomposition_nums: The number of search questions to generate.
url_per_query: The number of URLs to collect per search question.
system_text: The system text.
Returns:
A dictionary containing the search questions as keys and the collected URLs as values.
"""
system_text = system_text if system_text else RESEARCH_TOPIC_SYSTEM.format(topic=topic)
# Decompose the research question into multiple sub-problems
keywords = await self._aask(SEARCH_TOPIC_PROMPT, [system_text])
try:
keywords = OutputParser.extract_struct(keywords, list)
keywords = parse_obj_as(list[str], keywords)
except Exception as e:
logger.exception(f"fail to get keywords related to the research topic \"{topic}\" for {e}")
keywords = [topic]
# Search the sub-problems using the search engine
results = await asyncio.gather(*(self.search_engine.run(i, as_string=False) for i in keywords))
# Browse through the search engine results and filter out those relevant to the research question
def gen_msg():
while True:
search_results = "\n".join(f"#### Keyword: {i}\n Search Result: {j}\n" for (i, j) in zip(keywords, results))
prompt = SUMMARIZE_SEARCH_PROMPT.format(decomposition_nums=decomposition_nums, search_results=search_results)
yield prompt
remove = max(results, key=len)
remove.pop()
if len(remove) == 0:
break
prompt = reduce_message_length(gen_msg(), self.llm.model, system_text, CONFIG.max_tokens_rsp)
logger.debug(prompt)
queries = await self._aask(prompt, [system_text])
try:
queries = OutputParser.extract_struct(queries, list)
queries = parse_obj_as(list[str], queries)
except Exception as e:
logger.exception(f"fail to break down the research question due to {e}")
queries = keywords
ret = {}
# Sort and take the TopK URLs from the search results
for query in queries:
ret[query] = await self._search_and_rank_urls(topic, query, url_per_query)
return retWebBrowseAndSummarize
The WebBrowseAndSummarize Action is responsible for browsing web pages and summarizing their content. MetaGPT provides the WebBrowserEngine in the tools module, which supports web browsing through playwright/selenium. The WebBrowseAndSummarize Action uses the WebBrowserEngine for web browsing. The implementation details can be found in metagpt/actions/research.py, and the following provides a basic explanation of the WebBrowseAndSummarize.run method:
class WebBrowseAndSummarize(Action):
async def run(
self,
url: str,
*urls: str,
query: str,
system_text: str = RESEARCH_BASE_SYSTEM,
) -> dict[str, str]:
"""Run the action to browse the web and provide summaries.
Args:
url: The main URL to browse.
urls: Additional URLs to browse.
query: The research question.
system_text: The system text.
Returns:
A dictionary containing the URLs as keys and their summaries as values.
"""
# Web page browsing and content extraction
contents = await self.web_browser_engine.run(url, *urls)
if not urls:
contents = [contents]
# Web page content summarization
summaries = {}
prompt_template = WEB_BROWSE_AND_SUMMARIZE_PROMPT.format(query=query, content="{}")
for u, content in zip([url, *urls], contents):
content = content.inner_text
chunk_summaries = []
for prompt in generate_prompt_chunk(content, prompt_template, self.llm.model, system_text, CONFIG.max_tokens_rsp):
logger.debug(prompt)
summary = await self._aask(prompt, [system_text])
if summary == "Not relevant.":
continue
chunk_summaries.append(summary)
if not chunk_summaries:
summaries[u] = None
continue
if len(chunk_summaries) == 1:
summaries[u] = chunk_summaries[0]
continue
content = "\n".join(chunk_summaries)
prompt = WEB_BROWSE_AND_SUMMARIZE_PROMPT.format(query=query, content=content)
summary = await self._aask(prompt, [system_text])
summaries[u] = summary
return summariesclass WebBrowseAndSummarize(Action):
async def run(
self,
url: str,
*urls: str,
query: str,
system_text: str = RESEARCH_BASE_SYSTEM,
) -> dict[str, str]:
"""Run the action to browse the web and provide summaries.
Args:
url: The main URL to browse.
urls: Additional URLs to browse.
query: The research question.
system_text: The system text.
Returns:
A dictionary containing the URLs as keys and their summaries as values.
"""
# Web page browsing and content extraction
contents = await self.web_browser_engine.run(url, *urls)
if not urls:
contents = [contents]
# Web page content summarization
summaries = {}
prompt_template = WEB_BROWSE_AND_SUMMARIZE_PROMPT.format(query=query, content="{}")
for u, content in zip([url, *urls], contents):
content = content.inner_text
chunk_summaries = []
for prompt in generate_prompt_chunk(content, prompt_template, self.llm.model, system_text, CONFIG.max_tokens_rsp):
logger.debug(prompt)
summary = await self._aask(prompt, [system_text])
if summary == "Not relevant.":
continue
chunk_summaries.append(summary)
if not chunk_summaries:
summaries[u] = None
continue
if len(chunk_summaries) == 1:
summaries[u] = chunk_summaries[0]
continue
content = "\n".join(chunk_summaries)
prompt = WEB_BROWSE_AND_SUMMARIZE_PROMPT.format(query=query, content=content)
summary = await self._aask(prompt, [system_text])
summaries[u] = summary
return summariesConductResearch
The ConductResearch Action is responsible for writing a research report. It is implemented by using the summarized data from the WebBrowseAndSummarize Action as context and then generating the research report. The implementation details can be found in metagpt/actions/research.py, and the following provides a basic explanation of the ConductResearch.run method:
class ConductResearch(Action):
async def run(
self,
topic: str,
content: str,
system_text: str = RESEARCH_BASE_SYSTEM,
) -> str:
"""Run the action to conduct research and generate a research report.
Args:
topic: The research topic.
content: The content for research.
system_text: The system text.
Returns:
The generated research report.
"""
prompt = CONDUCT_RESEARCH_PROMPT.format(topic=topic, content=content)
logger.debug(prompt)
self.llm.auto_max_tokens = True
return await self._aask(prompt, [system_text])class ConductResearch(Action):
async def run(
self,
topic: str,
content: str,
system_text: str = RESEARCH_BASE_SYSTEM,
) -> str:
"""Run the action to conduct research and generate a research report.
Args:
topic: The research topic.
content: The content for research.
system_text: The system text.
Returns:
The generated research report.
"""
prompt = CONDUCT_RESEARCH_PROMPT.format(topic=topic, content=content)
logger.debug(prompt)
self.llm.auto_max_tokens = True
return await self._aask(prompt, [system_text])Role (Researcher)
The Researcher role combines the CollectLinks, WebBrowseAndSummarize, and ConductResearch Actions to enable the capability of searching the internet and summarizing reports. Therefore, these three Actions need to be added to the role during initialization using the set_actions method. Since these Actions are executed in the order of CollectLinks -> WebBrowseAndSummarize -> ConductResearch, the execution logic for these Actions needs to be defined in the react/_act methods. The implementation details can be found in metagpt/roles/researcher.py, and the following provides a basic explanation of the Researcher class:
class Researcher(Role):
def __init__(
self,
name: str = "David",
profile: str = "Researcher",
goal: str = "Gather information and conduct research",
constraints: str = "Ensure accuracy and relevance of information",
language: str = "en-us",
**kwargs,
):
super().__init__(name, profile, goal, constraints, **kwargs)
# Add the `CollectLinks`, `WebBrowseAndSummarize`, and `ConductResearch` actions
self.set_actions([CollectLinks(name), WebBrowseAndSummarize(name), ConductResearch(name)])
# Set to execute in order
self._set_react_mode(react_mode="by_order")
self.language = language
if language not in ("en-us", "zh-cn"):
logger.warning(f"The language `{language}` has not been tested, it may not work.")
async def _act(self) -> Message:
logger.info(f"{self._setting}: ready to {self.rc.todo}")
todo = self.rc.todo
msg = self.rc.memory.get(k=1)[0]
if isinstance(msg.instruct_content, Report):
instruct_content = msg.instruct_content
topic = instruct_content.topic
else:
topic = msg.content
research_system_text = get_research_system_text(topic, self.language)
# Search the internet and retrieve URL information
if isinstance(todo, CollectLinks):
links = await todo.run(topic, 4, 4)
ret = Message(content="", instruct_content=Report(topic=topic, links=links), role=self.profile, cause_by=todo)
# Browse web pages and summarize their content
elif isinstance(todo, WebBrowseAndSummarize):
links = instruct_content.links
todos = (todo.run(*url, query=query, system_text=research_system_text) for (query, url) in links.items())
summaries = await asyncio.gather(*todos)
summaries = list((url, summary) for i in summaries for (url, summary) in i.items() if summary)
ret = Message(content="", instruct_content=Report(topic=topic, summaries=summaries), role=self.profile, cause_by=todo)
# Generate a research report
else:
summaries = instruct_content.summaries
summary_text = "\n---\n".join(f"url: {url}\nsummary: {summary}" for (url, summary) in summaries)
content = await self.rc.todo.run(topic, summary_text, system_text=research_system_text)
ret = Message(content="", instruct_content=Report(topic=topic, content=content), role=self.profile, cause_by=type(self.rc.todo))
self.rc.memory.add(ret)
return ret
async def react(self) -> Message:
msg = await super().react()
report = msg.instruct_content
# Output the report
self.write_report(report.topic, report.content)
return msg
class Researcher(Role):
def __init__(
self,
name: str = "David",
profile: str = "Researcher",
goal: str = "Gather information and conduct research",
constraints: str = "Ensure accuracy and relevance of information",
language: str = "en-us",
**kwargs,
):
super().__init__(name, profile, goal, constraints, **kwargs)
# Add the `CollectLinks`, `WebBrowseAndSummarize`, and `ConductResearch` actions
self.set_actions([CollectLinks(name), WebBrowseAndSummarize(name), ConductResearch(name)])
# Set to execute in order
self._set_react_mode(react_mode="by_order")
self.language = language
if language not in ("en-us", "zh-cn"):
logger.warning(f"The language `{language}` has not been tested, it may not work.")
async def _act(self) -> Message:
logger.info(f"{self._setting}: ready to {self.rc.todo}")
todo = self.rc.todo
msg = self.rc.memory.get(k=1)[0]
if isinstance(msg.instruct_content, Report):
instruct_content = msg.instruct_content
topic = instruct_content.topic
else:
topic = msg.content
research_system_text = get_research_system_text(topic, self.language)
# Search the internet and retrieve URL information
if isinstance(todo, CollectLinks):
links = await todo.run(topic, 4, 4)
ret = Message(content="", instruct_content=Report(topic=topic, links=links), role=self.profile, cause_by=todo)
# Browse web pages and summarize their content
elif isinstance(todo, WebBrowseAndSummarize):
links = instruct_content.links
todos = (todo.run(*url, query=query, system_text=research_system_text) for (query, url) in links.items())
summaries = await asyncio.gather(*todos)
summaries = list((url, summary) for i in summaries for (url, summary) in i.items() if summary)
ret = Message(content="", instruct_content=Report(topic=topic, summaries=summaries), role=self.profile, cause_by=todo)
# Generate a research report
else:
summaries = instruct_content.summaries
summary_text = "\n---\n".join(f"url: {url}\nsummary: {summary}" for (url, summary) in summaries)
content = await self.rc.todo.run(topic, summary_text, system_text=research_system_text)
ret = Message(content="", instruct_content=Report(topic=topic, content=content), role=self.profile, cause_by=type(self.rc.todo))
self.rc.memory.add(ret)
return ret
async def react(self) -> Message:
msg = await super().react()
report = msg.instruct_content
# Output the report
self.write_report(report.topic, report.content)
return msgUsage Instructions
Dependencies and Configuration
The Researcher role depends on SearchEngine and WebBrowserEngine. Below are brief instructions for installing and configuring these components.
SearchEngine
Supports serpapi/google/serper/ddg search engines. They differ as follows:
| Name | Default Engine | Additional Dependency Packages | Installation |
|---|---|---|---|
| serpapi | √ | \ | \ |
| × | google-api-python-client | pip install metagpt\[search-google\] | |
| serper | × | \ | \ |
| ddg | × | duckduckgo-search | pip install metagpt\[search-ddg\] |
Configuration:
- serpapi
- search.engine: Set to serpapi
- search.api_key: Obtain from https://serpapi.com/
- search.params: Additional parameters to pass to the search engine, e.g.,
- google
- search.engine: Set to google
- search.api_key: Obtain from https://console.cloud.google.com/apis/credentials
- search.cse_id: Obtain from https://programmablesearchengine.google.com/controlpanel/create
- serper
- search.engine: Set to serper
- search.api_key: Obtain from https://serper.dev/
- ddg
- search.engine: Set to ddg
WebBrowserEngine
Supports playwright/selenium engines. To use them, additional dependencies must be installed. They differ as follows:
| Name | Default Engine | Additional Dependency Packages | Installation | Asynchronous | Supported Platforms |
|---|---|---|---|---|---|
| playwright | √ | playwright beautifulsoup4 | pip install metagpt\[playwright\] | Native | Partially supported platforms |
| selenium | × | selenium webdriver_manager beautifulsoup4 | pip install metagpt\[selenium\] | Thread Pool | Almost all platforms |
Configuration:
- playwright
- browser.engine: Set to playwright
- browser.browser_type: Supports chromium/firefox/webkit; defaults to chromium. More information: Playwright BrowserType
- selenium
- browser.engine: Set to selenium
- browser.browser_type: Supports chrome/firefox/edge/ie; defaults to chrome. More information: Selenium BrowserTypes
Running Examples and Results
The metagpt.roles.researcher module provides a command-line interface for executing the functionalities of the Researcher. An example is as follows:
python3 -m metagpt.roles.researcher "tensorflow vs. pytorch"python3 -m metagpt.roles.researcher "tensorflow vs. pytorch"Log output: log.txt Report output: dataiku vs. datarobot.md