Tool Usage: Web Scraping
Overview
Web scraping involves the extraction and understanding of web page content, providing users with more intelligent, customized information retrieval and analysis capabilities. We will implement this scenario requirement with DataInterpreter.
Example: Using the Tool to Obtain Table Data from a Static Web Page
Task
Retrieve paper information containing the keywords: multiagent and large language model from iclr-2024-statistics
Code
bash
python examples/di/crawl_webpage.pypython examples/di/crawl_webpage.pyExecution Results
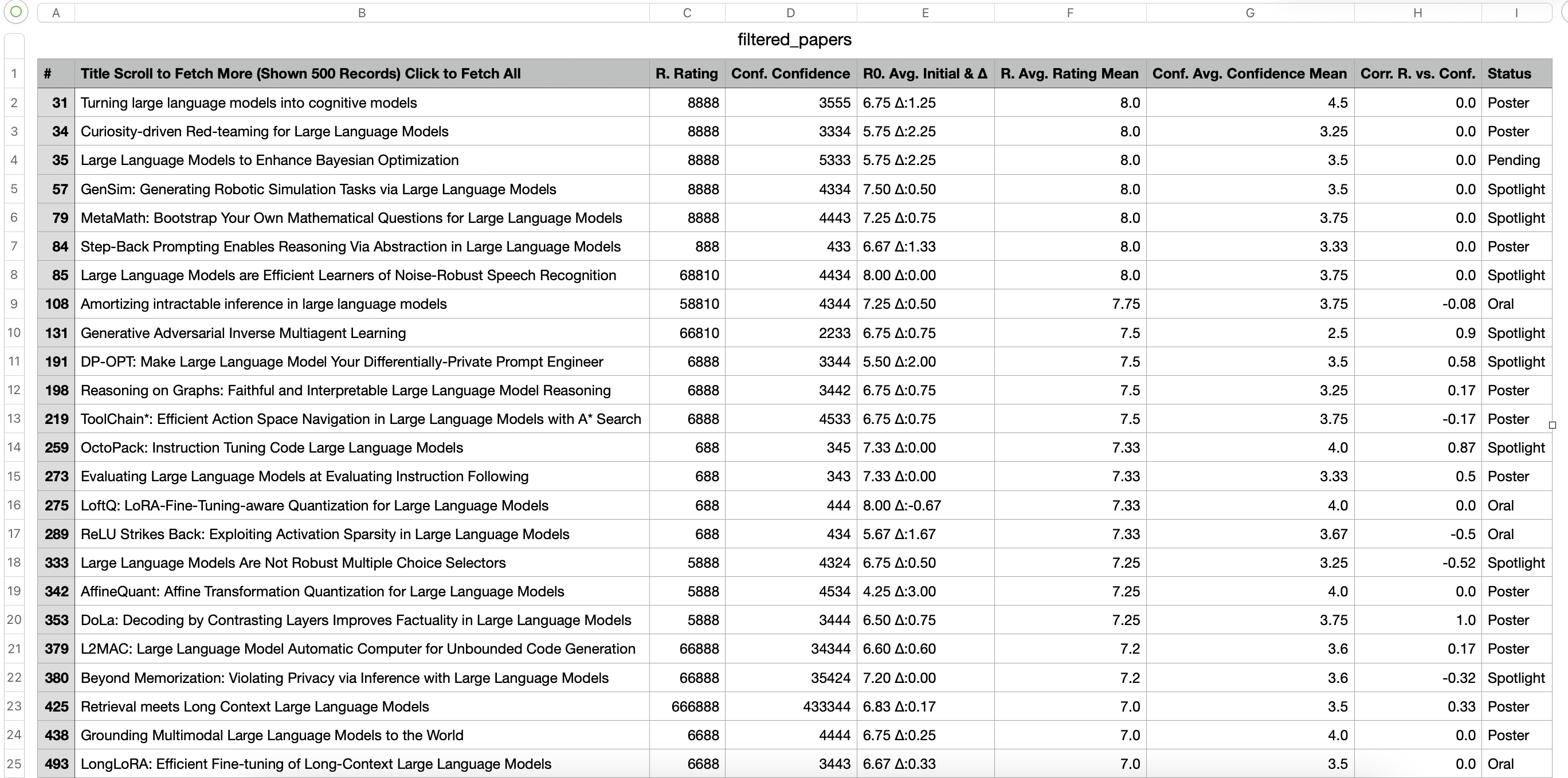
Mechanism Explained
- Use the tool function scrape_web_playwright from metagpt.tools.libs.web_scraping to obtain the webpage's HTML and inner text. This tool function is a wrapper for the browser automation library Playwright.
- Use BeautifulSoup to retrieve the table with the id paperlist, and load it as a pandas DataFrame.
- Obtain the column names of the DataFrame to locate the title column, match keywords multiagent, large language model to filter data. Save the filtered data in filtered_papers.csv.