收据助手:从收据中提取结构信息
角色介绍
功能说明
支持 pdf, png, jpg, zip 格式发票文件的 ocr 识别,生成收款人、城市、总金额、开票日期信息的 csv 文件。如果是 pdf, png, jpg 类型的发票文件,即单文件发票,可以提问发票内容相关的问题。同时,支持多语言发票结果生成。
设计思路
- 对于
pdf,png,jpg格式发票文件,通过开源的PaddleOCR API对发票文件进行ocr识别,再将ocr识别后的数据提供给llm大模型提取主要信息写入表格,最后提问llm大模型关于发票的内容。 - 对于
zip格式发票文件,先解压压缩包到指定目录,再递归遍历pdf,png,jpg格式发票文件进行ocr识别,再将ocr识别后的数据提供给llm大模型提取主要信息写入到同一个表格。多个文件不支持提问内容。
源码
角色定义
定义角色类,继承
Role基类,重写__init__初始化方法。__init__方法必须包含name、profile、goal、constraints参数。第一行代码使用super().__init__(name, profile, goal, constraints)调用父类的构造函数,实现Role的初始化。使用self._init_actions([InvoiceOCR])添加初始的action和states,这里先添加ocr识别发票的action。也可以自定义参数,这里加了language参数支持自定义语言。这里用filename,origin_query,orc_data分别暂存发票文件名、原始提问、ocr识别结果。使用self._set_react_mode(react_mode="by_order")将_init_actions的action执行顺序设置为顺序。pythonclass InvoiceOCRAssistant(Role): """Invoice OCR assistant, support OCR text recognition of invoice PDF, png, jpg, and zip files, generate a table for the payee, city, total amount, and invoicing date of the invoice, and ask questions for a single file based on the OCR recognition results of the invoice. Args: name: The name of the role. profile: The role profile description. goal: The goal of the role. constraints: Constraints or requirements for the role. language: The language in which the invoice table will be generated. """ def __init__( self, name: str = "Stitch", profile: str = "Invoice OCR Assistant", goal: str = "OCR identifies invoice files and generates invoice main information table", constraints: str = "", language: str = "ch", ): super().__init__(name, profile, goal, constraints) self._init_actions([InvoiceOCR]) self.language = language self.filename = "" self.origin_query = "" self.orc_data = None self._set_react_mode(react_mode="by_order")class InvoiceOCRAssistant(Role): """Invoice OCR assistant, support OCR text recognition of invoice PDF, png, jpg, and zip files, generate a table for the payee, city, total amount, and invoicing date of the invoice, and ask questions for a single file based on the OCR recognition results of the invoice. Args: name: The name of the role. profile: The role profile description. goal: The goal of the role. constraints: Constraints or requirements for the role. language: The language in which the invoice table will be generated. """ def __init__( self, name: str = "Stitch", profile: str = "Invoice OCR Assistant", goal: str = "OCR identifies invoice files and generates invoice main information table", constraints: str = "", language: str = "ch", ): super().__init__(name, profile, goal, constraints) self._init_actions([InvoiceOCR]) self.language = language self.filename = "" self.origin_query = "" self.orc_data = None self._set_react_mode(react_mode="by_order")重写
_act方法,_act方法是执行action。在Role类的_react方法会循环执行think和action操作,_think方法会根据states思考下一步执行的action,因此只需重写_act方法。使用msg = self._rc.memory.get(k=1)[0]获取上下文最新的消息,使用todo = self._rc.todo从上下文获取下一步要执行的action。这里先通过InvoiceOCR识别发票文件数据,如果只识别单张发票,则添加GenerateTable,ReplyQuestion的action,多张发票文件就不需要ReplyQuestion的action;再通过GenerateTable的action将发票识别结果提供给llm大模型抽取主要信息后下载为表格文件;如果是单张发票文件再将提问和识别结果发给llm大模型获取答案。每一步action的结果生成message,再通过self._rc.memory.add(msg)放到上下文。pythonasync def _act(self) -> Message: """Perform an action as determined by the role. Returns: A message containing the result of the action. """ msg = self._rc.memory.get(k=1)[0] todo = self._rc.todo if isinstance(todo, InvoiceOCR): self.origin_query = msg.content file_path = msg.instruct_content.get("file_path") self.filename = file_path.name if not file_path: raise Exception("Invoice file not uploaded") resp = await todo.run(file_path) if len(resp) == 1: # Single file support for questioning based on OCR recognition results self._init_actions([GenerateTable, ReplyQuestion]) self.orc_data = resp[0] else: self._init_actions([GenerateTable]) self._rc.todo = None content = INVOICE_OCR_SUCCESS elif isinstance(todo, GenerateTable): ocr_results = msg.instruct_content resp = await todo.run(ocr_results, self.filename) # Convert list to Markdown format string df = pd.DataFrame(resp) markdown_table = df.to_markdown(index=False) content = f"{markdown_table}\n\n\n" else: resp = await todo.run(self.origin_query, self.orc_data) content = resp msg = Message(content=content, instruct_content=resp) self._rc.memory.add(msg) return msgasync def _act(self) -> Message: """Perform an action as determined by the role. Returns: A message containing the result of the action. """ msg = self._rc.memory.get(k=1)[0] todo = self._rc.todo if isinstance(todo, InvoiceOCR): self.origin_query = msg.content file_path = msg.instruct_content.get("file_path") self.filename = file_path.name if not file_path: raise Exception("Invoice file not uploaded") resp = await todo.run(file_path) if len(resp) == 1: # Single file support for questioning based on OCR recognition results self._init_actions([GenerateTable, ReplyQuestion]) self.orc_data = resp[0] else: self._init_actions([GenerateTable]) self._rc.todo = None content = INVOICE_OCR_SUCCESS elif isinstance(todo, GenerateTable): ocr_results = msg.instruct_content resp = await todo.run(ocr_results, self.filename) # Convert list to Markdown format string df = pd.DataFrame(resp) markdown_table = df.to_markdown(index=False) content = f"{markdown_table}\n\n\n" else: resp = await todo.run(self.origin_query, self.orc_data) content = resp msg = Message(content=content, instruct_content=resp) self._rc.memory.add(msg) return msg
Action定义
定义
action,每个action对应一个class对象,继承Action基类,重写__init__初始化方法。。__init__方法包含name参数。第一行代码使用super().__init__(name, *args, **kwargs)调用父类的构造函数,实现action的初始化。这里使用args、kwargs将其他参数传递给父类的构造函数,比如context、llm。pythonclass InvoiceOCR(Action): """Action class for performing OCR on invoice files, including zip, PDF, png, and jpg files. Args: name: The name of the action. Defaults to an empty string. language: The language for OCR output. Defaults to "ch" (Chinese). """ def __init__(self, name: str = "", *args, **kwargs): super().__init__(name, *args, **kwargs)class InvoiceOCR(Action): """Action class for performing OCR on invoice files, including zip, PDF, png, and jpg files. Args: name: The name of the action. Defaults to an empty string. language: The language for OCR output. Defaults to "ch" (Chinese). """ def __init__(self, name: str = "", *args, **kwargs): super().__init__(name, *args, **kwargs)重写
run方法。run方法是action执行的主要函数。InvoiceOCR对于pdf,png,jpg格式发票文件,通过开源的PaddleOCR API对发票文件进行ocr识别,对于zip格式发票文件,先解压压缩包到指定目录,再递归遍历pdf,png,jpg格式发票文件分别进行ocr识别。pythonasync def run(self, file_path: Path, *args, **kwargs) -> list: """Execute the action to identify invoice files through OCR. Args: file_path: The path to the input file. Returns: A list of OCR results. """ file_ext = await self._check_file_type(file_path) if file_ext == ".zip": # OCR recognizes zip batch files unzip_path = await self._unzip(file_path) ocr_list = [] for root, _, files in os.walk(unzip_path): for filename in files: invoice_file_path = Path(root) / Path(filename) # Identify files that match the type if Path(filename).suffix in [".zip", ".pdf", ".png", ".jpg"]: ocr_result = await self._ocr(str(invoice_file_path)) ocr_list.append(ocr_result) return ocr_list else: # OCR identifies single file ocr_result = await self._ocr(file_path) return [ocr_result] @staticmethod async def _check_file_type(file_path: Path) -> str: """Check the file type of the given filename. Args: file_path: The path of the file. Returns: The file type based on FileExtensionType enum. Raises: Exception: If the file format is not zip, pdf, png, or jpg. """ ext = file_path.suffix if ext not in [".zip", ".pdf", ".png", ".jpg"]: raise Exception("The invoice format is not zip, pdf, png, or jpg") return ext @staticmethod async def _unzip(file_path: Path) -> Path: """Unzip a file and return the path to the unzipped directory. Args: file_path: The path to the zip file. Returns: The path to the unzipped directory. """ file_directory = file_path.parent / "unzip_invoices" / datetime.now().strftime("%Y%m%d%H%M%S") with zipfile.ZipFile(file_path, "r") as zip_ref: for zip_info in zip_ref.infolist(): # Use CP437 to encode the file name, and then use GBK decoding to prevent Chinese garbled code relative_name = Path(zip_info.filename.encode("cp437").decode("gbk")) if relative_name.suffix: full_filename = file_directory / relative_name await File.write(full_filename.parent, relative_name.name, zip_ref.read(zip_info.filename)) logger.info(f"unzip_path: {file_directory}") return file_directory @staticmethod async def _ocr(invoice_file_path: Path): ocr = PaddleOCR(use_angle_cls=True, lang="ch", page_num=1) ocr_result = ocr.ocr(str(invoice_file_path), cls=True) return ocr_resultasync def run(self, file_path: Path, *args, **kwargs) -> list: """Execute the action to identify invoice files through OCR. Args: file_path: The path to the input file. Returns: A list of OCR results. """ file_ext = await self._check_file_type(file_path) if file_ext == ".zip": # OCR recognizes zip batch files unzip_path = await self._unzip(file_path) ocr_list = [] for root, _, files in os.walk(unzip_path): for filename in files: invoice_file_path = Path(root) / Path(filename) # Identify files that match the type if Path(filename).suffix in [".zip", ".pdf", ".png", ".jpg"]: ocr_result = await self._ocr(str(invoice_file_path)) ocr_list.append(ocr_result) return ocr_list else: # OCR identifies single file ocr_result = await self._ocr(file_path) return [ocr_result] @staticmethod async def _check_file_type(file_path: Path) -> str: """Check the file type of the given filename. Args: file_path: The path of the file. Returns: The file type based on FileExtensionType enum. Raises: Exception: If the file format is not zip, pdf, png, or jpg. """ ext = file_path.suffix if ext not in [".zip", ".pdf", ".png", ".jpg"]: raise Exception("The invoice format is not zip, pdf, png, or jpg") return ext @staticmethod async def _unzip(file_path: Path) -> Path: """Unzip a file and return the path to the unzipped directory. Args: file_path: The path to the zip file. Returns: The path to the unzipped directory. """ file_directory = file_path.parent / "unzip_invoices" / datetime.now().strftime("%Y%m%d%H%M%S") with zipfile.ZipFile(file_path, "r") as zip_ref: for zip_info in zip_ref.infolist(): # Use CP437 to encode the file name, and then use GBK decoding to prevent Chinese garbled code relative_name = Path(zip_info.filename.encode("cp437").decode("gbk")) if relative_name.suffix: full_filename = file_directory / relative_name await File.write(full_filename.parent, relative_name.name, zip_ref.read(zip_info.filename)) logger.info(f"unzip_path: {file_directory}") return file_directory @staticmethod async def _ocr(invoice_file_path: Path): ocr = PaddleOCR(use_angle_cls=True, lang="ch", page_num=1) ocr_result = ocr.ocr(str(invoice_file_path), cls=True) return ocr_result其他
action写法类似。GenerateTable将ocr识别后的数据提供给llm大模型提取主要信息写入表格;ReplyQuestion提问llm大模型关于发票的内容。pythonclass GenerateTable(Action): """Action class for generating tables from OCR results. Args: name: The name of the action. Defaults to an empty string. language: The language used for the generated table. Defaults to "ch" (Chinese). """ def __init__(self, name: str = "", language: str = "ch", *args, **kwargs): super().__init__(name, *args, **kwargs) self.language = language async def run(self, ocr_results: list, filename: str, *args, **kwargs) -> dict[str, str]: """Processes OCR results, extracts invoice information, generates a table, and saves it as an Excel file. Args: ocr_results: A list of OCR results obtained from invoice processing. filename: The name of the output Excel file. Returns: A dictionary containing the invoice information. """ table_data = [] pathname = INVOICE_OCR_TABLE_PATH pathname.mkdir(parents=True, exist_ok=True) for ocr_result in ocr_results: # Extract invoice OCR main information prompt = EXTRACT_OCR_MAIN_INFO_PROMPT.format(ocr_result=ocr_result, language=self.language) ocr_info = await self._aask(prompt=prompt) invoice_data = OutputParser.extract_struct(ocr_info, dict) if invoice_data: table_data.append(invoice_data) # Generate Excel file filename = f"{filename.split('.')[0]}.xlsx" full_filename = f"{pathname}/{filename}" df = pd.DataFrame(table_data) df.to_excel(full_filename, index=False) return table_data class ReplyQuestion(Action): """Action class for generating replies to questions based on OCR results. Args: name: The name of the action. Defaults to an empty string. language: The language used for generating the reply. Defaults to "ch" (Chinese). """ def __init__(self, name: str = "", language: str = "ch", *args, **kwargs): super().__init__(name, *args, **kwargs) self.language = language async def run(self, query: str, ocr_result: list, *args, **kwargs) -> str: """Reply to questions based on ocr results. Args: query: The question for which a reply is generated. ocr_result: A list of OCR results. Returns: A reply result of string type. """ prompt = REPLY_OCR_QUESTION_PROMPT.format(query=query, ocr_result=ocr_result, language=self.language) resp = await self._aask(prompt=prompt) return respclass GenerateTable(Action): """Action class for generating tables from OCR results. Args: name: The name of the action. Defaults to an empty string. language: The language used for the generated table. Defaults to "ch" (Chinese). """ def __init__(self, name: str = "", language: str = "ch", *args, **kwargs): super().__init__(name, *args, **kwargs) self.language = language async def run(self, ocr_results: list, filename: str, *args, **kwargs) -> dict[str, str]: """Processes OCR results, extracts invoice information, generates a table, and saves it as an Excel file. Args: ocr_results: A list of OCR results obtained from invoice processing. filename: The name of the output Excel file. Returns: A dictionary containing the invoice information. """ table_data = [] pathname = INVOICE_OCR_TABLE_PATH pathname.mkdir(parents=True, exist_ok=True) for ocr_result in ocr_results: # Extract invoice OCR main information prompt = EXTRACT_OCR_MAIN_INFO_PROMPT.format(ocr_result=ocr_result, language=self.language) ocr_info = await self._aask(prompt=prompt) invoice_data = OutputParser.extract_struct(ocr_info, dict) if invoice_data: table_data.append(invoice_data) # Generate Excel file filename = f"{filename.split('.')[0]}.xlsx" full_filename = f"{pathname}/{filename}" df = pd.DataFrame(table_data) df.to_excel(full_filename, index=False) return table_data class ReplyQuestion(Action): """Action class for generating replies to questions based on OCR results. Args: name: The name of the action. Defaults to an empty string. language: The language used for generating the reply. Defaults to "ch" (Chinese). """ def __init__(self, name: str = "", language: str = "ch", *args, **kwargs): super().__init__(name, *args, **kwargs) self.language = language async def run(self, query: str, ocr_result: list, *args, **kwargs) -> str: """Reply to questions based on ocr results. Args: query: The question for which a reply is generated. ocr_result: A list of OCR results. Returns: A reply result of string type. """ prompt = REPLY_OCR_QUESTION_PROMPT.format(query=query, ocr_result=ocr_result, language=self.language) resp = await self._aask(prompt=prompt) return resp
角色执行结果
输入样例
样例 1
发票图片

输入代码如下,将
path替换为发票文件相对路径。pythonrole = InvoiceOCRAssistant() await role.run(Message(content="Invoicing date", instruct_content={"file_path": path}))role = InvoiceOCRAssistant() await role.run(Message(content="Invoicing date", instruct_content={"file_path": path}))
样例 2
发票图片

输入代码如下,将
path替换为发票文件相对路径。pythonrole = InvoiceOCRAssistant() await role.run(Message(content="Payee", instruct_content={"file_path": path}))role = InvoiceOCRAssistant() await role.run(Message(content="Payee", instruct_content={"file_path": path}))
执行命令样例
在项目根目录下,执行命令行 python3 /examples/invoice_ocr.py。
执行结果
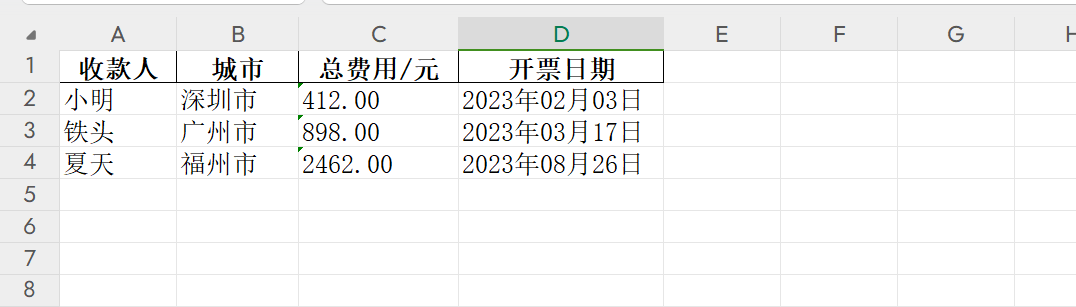
生成的发票信息在项 xlsx 文件在项目根目录下的 /data/invoice_ocr 目录下。截图如下:
注意点
该角色最好使用长文本限制较大的 llm 大模型 api,比如 gpt-3.5-turbo-16k,避免 ocr 识别结果太大与 llm 大模型交互时被限制。