Recepit Assistant: Extract Structural Info from Receipts
Role Introduction
Function Description
Supports OCR recognition of invoice files in pdf, png, jpg, and zip formats, generating a csv file with information on the payee, city, total amount, and invoicing date. For single-file invoices in pdf, png, jpg formats, you can ask questions related to the invoice content. Additionally, multi-language support is provided for the generated invoice results.
Design Concept
- For
pdf,png,jpgformat invoice files, use the open-sourcePaddleOCR APIfor OCR recognition. Extract the OCR-recognized data using theLLMlarge model and write it to a table. Finally, ask theLLMlarge model about the invoice content. - For
zipformat invoice files, first unzip the compressed package to a specified directory. Then, recursively traversepdf,png,jpgformat invoice files for OCR recognition. Provide the OCR-recognized data to theLLMlarge model to extract key information into the same table. Asking questions about content is not supported for multiple files.
Source Code
Role Definition
Define the role class, inherit from the
Rolebase class, and override the__init__initialization method. The__init__method must include thename,profile,goal, andconstraintsparameters. The first line of code usessuper().__init__(name, profile, goal, constraints)to call the constructor of the parent class, implementing the initialization of theRole. Useself._init_actions([InvoiceOCR])to add initial actions and states. Here, the initial action is to add an action for OCR recognition of invoices. Custom parameters can also be added; here, thelanguageparameter is added to support custom languages. Variables such asfilename,origin_query, andorc_dataare used to temporarily store the invoice file name, the original query, and the OCR recognition result, respectively. Useself._set_react_mode(react_mode="by_order")to set the execution order of actions to be sequential in the_init_actions.pythonclass InvoiceOCRAssistant(Role): """Invoice OCR assistant, support OCR text recognition of invoice PDF, png, jpg, and zip files, generate a table for the payee, city, total amount, and invoicing date of the invoice, and ask questions for a single file based on the OCR recognition results of the invoice. Args: name: The name of the role. profile: The role profile description. goal: The goal of the role. constraints: Constraints or requirements for the role. language: The language in which the invoice table will be generated. """ def __init__( self, name: str = "Stitch", profile: str = "Invoice OCR Assistant", goal: str = "OCR identifies invoice files and generates invoice main information table", constraints: str = "", language: str = "ch", ): super().__init__(name, profile, goal, constraints) self._init_actions([InvoiceOCR]) self.language = language self.filename = "" self.origin_query = "" self.orc_data = None self._set_react_mode(react_mode="by_order")class InvoiceOCRAssistant(Role): """Invoice OCR assistant, support OCR text recognition of invoice PDF, png, jpg, and zip files, generate a table for the payee, city, total amount, and invoicing date of the invoice, and ask questions for a single file based on the OCR recognition results of the invoice. Args: name: The name of the role. profile: The role profile description. goal: The goal of the role. constraints: Constraints or requirements for the role. language: The language in which the invoice table will be generated. """ def __init__( self, name: str = "Stitch", profile: str = "Invoice OCR Assistant", goal: str = "OCR identifies invoice files and generates invoice main information table", constraints: str = "", language: str = "ch", ): super().__init__(name, profile, goal, constraints) self._init_actions([InvoiceOCR]) self.language = language self.filename = "" self.origin_query = "" self.orc_data = None self._set_react_mode(react_mode="by_order")Override the
_actmethod. The_actmethod is responsible for executing actions. TheRoleclass's_reactmethod cyclically performsthinkandactionoperations. The_thinkmethod considers the next action to be performed based on thestates. Therefore, only the_actmethod needs to be overridden. Usemsg = self._rc.memory.get(k=1)[0]to get the latest message from the context. Usetodo = self._rc.todoto get the next action to be executed from the context. Here, the invoice data is recognized throughInvoiceOCR. If only a single invoice is recognized, addGenerateTableandReplyQuestionactions. If multiple invoice files are recognized, theReplyQuestionaction is not needed. Use theGenerateTableaction to provide the invoice recognition results to theLLMlarge model for extracting key information and downloading it as a table file. If it is a single invoice file, send the query and recognition results to theLLMlarge model to get the answer. The result of each action is turned into amessage, and it is added to the context usingself._rc.memory.add(msg).pythonasync def _act(self) -> Message: """Perform an action as determined by the role. Returns: A message containing the result of the action. """ msg = self._rc.memory.get(k=1)[0] todo = self._rc.todo if isinstance(todo, InvoiceOCR): self.origin_query = msg.content file_path = msg.instruct_content.get("file_path") self.filename = file_path.name if not file_path: raise Exception("Invoice file not uploaded") resp = await todo.run(file_path) if len(resp) == 1: # Single file support for questioning based on OCR recognition results self._init_actions([GenerateTable, ReplyQuestion]) self.orc_data = resp[0] else: self._init_actions([GenerateTable]) self._rc.todo = None content = INVOICE_OCR_SUCCESS elif isinstance(todo, GenerateTable): ocr_results = msg.instruct_content resp = await todo.run(ocr_results, self.filename) # Convert list to Markdown format string df = pd.DataFrame(resp) markdown_tableasync def _act(self) -> Message: """Perform an action as determined by the role. Returns: A message containing the result of the action. """ msg = self._rc.memory.get(k=1)[0] todo = self._rc.todo if isinstance(todo, InvoiceOCR): self.origin_query = msg.content file_path = msg.instruct_content.get("file_path") self.filename = file_path.name if not file_path: raise Exception("Invoice file not uploaded") resp = await todo.run(file_path) if len(resp) == 1: # Single file support for questioning based on OCR recognition results self._init_actions([GenerateTable, ReplyQuestion]) self.orc_data = resp[0] else: self._init_actions([GenerateTable]) self._rc.todo = None content = INVOICE_OCR_SUCCESS elif isinstance(todo, GenerateTable): ocr_results = msg.instruct_content resp = await todo.run(ocr_results, self.filename) # Convert list to Markdown format string df = pd.DataFrame(resp) markdown_table
Action Definition
Define an
action, where eachactioncorresponds to aclassobject. Inherit from theActionbase class and override the__init__initialization method. The__init__method includes thenameparameter. The first line of code usessuper().__init__(name, *args, **kwargs)to call the parent class constructor, implementing the initialization of theaction. Here, useargsandkwargsto pass other parameters to the parent class constructor, such ascontextandllm.pythonclass InvoiceOCR(Action): """Action class for performing OCR on invoice files, including zip, PDF, png, and jpg files. Args: name: The name of the action. Defaults to an empty string. language: The language for OCR output. Defaults to "ch" (Chinese). """ def __init__(self, name: str = "", *args, **kwargs): super().__init__(name, *args, **kwargs)class InvoiceOCR(Action): """Action class for performing OCR on invoice files, including zip, PDF, png, and jpg files. Args: name: The name of the action. Defaults to an empty string. language: The language for OCR output. Defaults to "ch" (Chinese). """ def __init__(self, name: str = "", *args, **kwargs): super().__init__(name, *args, **kwargs)Override the
runmethod. Therunmethod is the main function for executing theaction. ForInvoiceOCR, forpdf,png,jpgformat invoice files, use the open-sourcePaddleOCR APIfor OCR recognition. Forzipformat invoice files, unzip the compressed package to a specified directory, then recursively traversepdf,png,jpgformat invoice files, and perform OCR recognition on each file.pythonasync def run(self, file_path: Path, *args, **kwargs) -> list: """Execute the action to identify invoice files through OCR. Args: file_path: The path to the input file. Returns: A list of OCR results. """ file_ext = await self._check_file_type(file_path) if file_ext == ".zip": # OCR recognizes zip batch files unzip_path = await self._unzip(file_path) ocr_list = [] for root, _, files in os.walk(unzip_path): for filename in files: invoice_file_path = Path(root) / Path(filename) # Identify files that match the type if Path(filename).suffix in [".zip", ".pdf", ".png", ".jpg"]: ocr_result = await self._ocr(str(invoice_file_path)) ocr_list.append(ocr_result) return ocr_list else: # OCR identifies single file ocr_result = await self._ocr(file_path) return [ocr_result] @staticmethod async def _check_file_type(file_path: Path) -> str: """Check the file type of the given filename. Args: file_path: The path of the file. Returns: The file type based on FileExtensionType enum. Raises: Exception: If the file format is not zip, pdf, png, or jpg. """ ext = file_path.suffix if ext not in [".zip", ".pdf", ".png", ".jpg"]: raise Exception("The invoice format is not zip, pdf, png, or jpg") return ext @staticmethod async def _unzip(file_path: Path) -> Path: """Unzip a file and return the path to the unzipped directory. Args: file_path: The path to the zip file. Returns: The path to the unzipped directory. """ file_directory = file_path.parent / "unzip_invoices" / datetime.now().strftime("%Y%m%d%H%M%S") with zipfile.ZipFile(file_path, "r") as zip_ref: for zip_info in zip_ref.infolist(): # Use CP437 to encode the file name, and then use GBK decoding to prevent Chinese garbled code relative_name = Path(zip_info.filename.encode("cp437").decode("gbk")) if relative_name.suffix: full_filename = file_directory / relative_name await File.write(full_filename.parent, relative_name.name, zip_ref.read(zip_info.filename)) logger.info(f"unzip_path: {file_directory}") return file_directory @staticmethod async def _ocr(invoice_file_path: Path): ocr = PaddleOCR(use_angle_cls=True, lang="ch", page_num=1) ocr_result = ocr.ocr(str(invoice_file_path), cls=True) return ocr_resultasync def run(self, file_path: Path, *args, **kwargs) -> list: """Execute the action to identify invoice files through OCR. Args: file_path: The path to the input file. Returns: A list of OCR results. """ file_ext = await self._check_file_type(file_path) if file_ext == ".zip": # OCR recognizes zip batch files unzip_path = await self._unzip(file_path) ocr_list = [] for root, _, files in os.walk(unzip_path): for filename in files: invoice_file_path = Path(root) / Path(filename) # Identify files that match the type if Path(filename).suffix in [".zip", ".pdf", ".png", ".jpg"]: ocr_result = await self._ocr(str(invoice_file_path)) ocr_list.append(ocr_result) return ocr_list else: # OCR identifies single file ocr_result = await self._ocr(file_path) return [ocr_result] @staticmethod async def _check_file_type(file_path: Path) -> str: """Check the file type of the given filename. Args: file_path: The path of the file. Returns: The file type based on FileExtensionType enum. Raises: Exception: If the file format is not zip, pdf, png, or jpg. """ ext = file_path.suffix if ext not in [".zip", ".pdf", ".png", ".jpg"]: raise Exception("The invoice format is not zip, pdf, png, or jpg") return ext @staticmethod async def _unzip(file_path: Path) -> Path: """Unzip a file and return the path to the unzipped directory. Args: file_path: The path to the zip file. Returns: The path to the unzipped directory. """ file_directory = file_path.parent / "unzip_invoices" / datetime.now().strftime("%Y%m%d%H%M%S") with zipfile.ZipFile(file_path, "r") as zip_ref: for zip_info in zip_ref.infolist(): # Use CP437 to encode the file name, and then use GBK decoding to prevent Chinese garbled code relative_name = Path(zip_info.filename.encode("cp437").decode("gbk")) if relative_name.suffix: full_filename = file_directory / relative_name await File.write(full_filename.parent, relative_name.name, zip_ref.read(zip_info.filename)) logger.info(f"unzip_path: {file_directory}") return file_directory @staticmethod async def _ocr(invoice_file_path: Path): ocr = PaddleOCR(use_angle_cls=True, lang="ch", page_num=1) ocr_result = ocr.ocr(str(invoice_file_path), cls=True) return ocr_resultOther
actionimplementations are similar.GenerateTableprovides OCR-recognized data to theLLMlarge model to extract key information and write it to a table.ReplyQuestionasks theLLMlarge model about the content of the invoice.pythonclass GenerateTable(Action): """Action class for generating tables from OCR results. Args: name: The name of the action. Defaults to an empty string. language: The language used for the generated table. Defaults to "ch" (Chinese). """ def __init__(self, name: str = "", language: str = "ch", *args, **kwargs): super().__init__(name, *args, **kwargs) self.language = language async def run(self, ocr_results: list, filename: str, *args, **kwargs) -> dict[str, str]: """Processes OCR results, extracts invoice information, generates a table, and saves it as an Excel file. Args: ocr_results: A list of OCR results obtained from invoice processing. filename: The name of the output Excel file. Returns: A dictionary containing the invoice information. """ table_data = [] pathname = INVOICE_OCR_TABLE_PATH pathname.mkdir(parents=True, exist_ok=True) for ocr_result in ocr_results: # Extract invoice OCR main information prompt = EXTRACT_OCR_MAIN_INFO_PROMPT.format(ocr_result=ocr_result, language=self.language) ocr_info = await self._aask(prompt=prompt) invoice_data = OutputParser.extract_struct(ocr_info, dict) if invoice_data: table_data.append(invoice_data) # Generate Excel file filename = f"{filename.split('.')[0]}.xlsx" full_filename = f"{pathname}/{filename}" df = pd.DataFrame(table_data) df.to_excel(full_filename, index=False) return table_data class ReplyQuestion(Action): """Action class for generating replies to questions based on OCR results. Args: name: The name of the action. Defaults to an empty string. language: The language used for generating the reply. Defaults to "ch" (Chinese). """ def __init__(self, name: str = "", language: str = "ch", *args, **kwargs): super().__init__(name, *args, **kwargs) self.language = language async def run(self, query: str, ocr_result: list, *args, **kwargs) -> str: """Reply to questions based on ocr results. Args: query: The question for which a reply is generated. ocr_result: A list of OCR results. Returns: A reply result of string type. """ prompt = REPLY_OCR_QUESTION_PROMPT.format(query=query, ocr_result=ocr_result, language=self.language) resp = await self._aask(prompt=prompt) return respclass GenerateTable(Action): """Action class for generating tables from OCR results. Args: name: The name of the action. Defaults to an empty string. language: The language used for the generated table. Defaults to "ch" (Chinese). """ def __init__(self, name: str = "", language: str = "ch", *args, **kwargs): super().__init__(name, *args, **kwargs) self.language = language async def run(self, ocr_results: list, filename: str, *args, **kwargs) -> dict[str, str]: """Processes OCR results, extracts invoice information, generates a table, and saves it as an Excel file. Args: ocr_results: A list of OCR results obtained from invoice processing. filename: The name of the output Excel file. Returns: A dictionary containing the invoice information. """ table_data = [] pathname = INVOICE_OCR_TABLE_PATH pathname.mkdir(parents=True, exist_ok=True) for ocr_result in ocr_results: # Extract invoice OCR main information prompt = EXTRACT_OCR_MAIN_INFO_PROMPT.format(ocr_result=ocr_result, language=self.language) ocr_info = await self._aask(prompt=prompt) invoice_data = OutputParser.extract_struct(ocr_info, dict) if invoice_data: table_data.append(invoice_data) # Generate Excel file filename = f"{filename.split('.')[0]}.xlsx" full_filename = f"{pathname}/{filename}" df = pd.DataFrame(table_data) df.to_excel(full_filename, index=False) return table_data class ReplyQuestion(Action): """Action class for generating replies to questions based on OCR results. Args: name: The name of the action. Defaults to an empty string. language: The language used for generating the reply. Defaults to "ch" (Chinese). """ def __init__(self, name: str = "", language: str = "ch", *args, **kwargs): super().__init__(name, *args, **kwargs) self.language = language async def run(self, query: str, ocr_result: list, *args, **kwargs) -> str: """Reply to questions based on ocr results. Args: query: The question for which a reply is generated. ocr_result: A list of OCR results. Returns: A reply result of string type. """ prompt = REPLY_OCR_QUESTION_PROMPT.format(query=query, ocr_result=ocr_result, language=self.language) resp = await self._aask(prompt=prompt) return resp
Role Execution Results
Input Examples
Example 1
Invoice Image

Input code as follows, replace
pathwith the relative path to the invoice file.pythonrole = InvoiceOCRAssistant() await role.run(Message(content="Invoicing date", instruct_content={"file_path": path}))role = InvoiceOCRAssistant() await role.run(Message(content="Invoicing date", instruct_content={"file_path": path}))
Example 2
Invoice Image

Input code as follows, replace
pathwith the relative path to the invoice file.pythonrole = InvoiceOCRAssistant() await role.run(Message(content="Payee", instruct_content={"file_path": path}))role = InvoiceOCRAssistant() await role.run(Message(content="Payee", instruct_content={"file_path": path}))
Execution Command Example
In the project's root directory, execute the command python3 /examples/invoice_ocr.py.
Execution Results
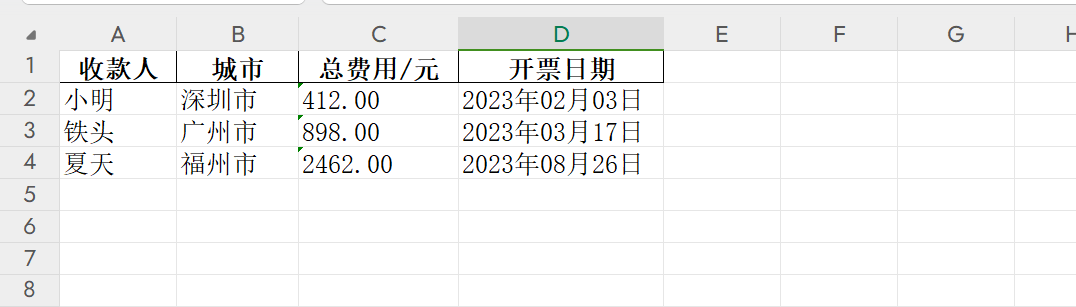
The generated invoice information is in the xlsx file in the /data/invoice_ocr directory at the project's root. Screenshots are as follows:
Note
It is recommended to use a large text limit llm model api, such as gpt-3.5-turbo-16k, for this role. This helps to avoid limitations when interacting with the llm large model due to excessively large OCR recognition results.