调研员:从网络进行搜索并总结报告
引言
背景
在MetaGPT中,调研员角色,可以根据用户的调研问题,从互联网上进行搜索总结,并最终生成报告。本文将从设计思路、代码实现、使用示例等几个方面介绍调研员角色。
目标
通过本文档,你可以了解如何使用MetaGPT的调研员角色进行网络搜索并总结报告,进一步地,可以使用MetaGPT的联网功能开发新的智能体
源码
设计说明
设计思路
在使用MetaGPT开发Researcher角色之前,我们需要先思考一下假如自己作为一个Researcher,在网络上搜索并输出调研报告是怎么做的。一般是包含以下几个步骤:
- 分析待研究的问题,并将问题拆分成几个可以适合用搜索引擎进行搜索的子问题
- 通过搜索引擎搜索子问题,浏览搜索引擎会给出多个带有标题、原文Url、摘要等信息的搜索结果,判断每一条搜索结果是否与要搜索的问题相关以及信息来源是否可靠,从而选择是否要进一步通过Url浏览网页
- 点击需要进一步浏览的网页,判断网页内容对待研究的问题是否有帮助,提取有关的信息并记录
- 聚合所有的记录下来的相关资料,针对待研究的问题撰写报告
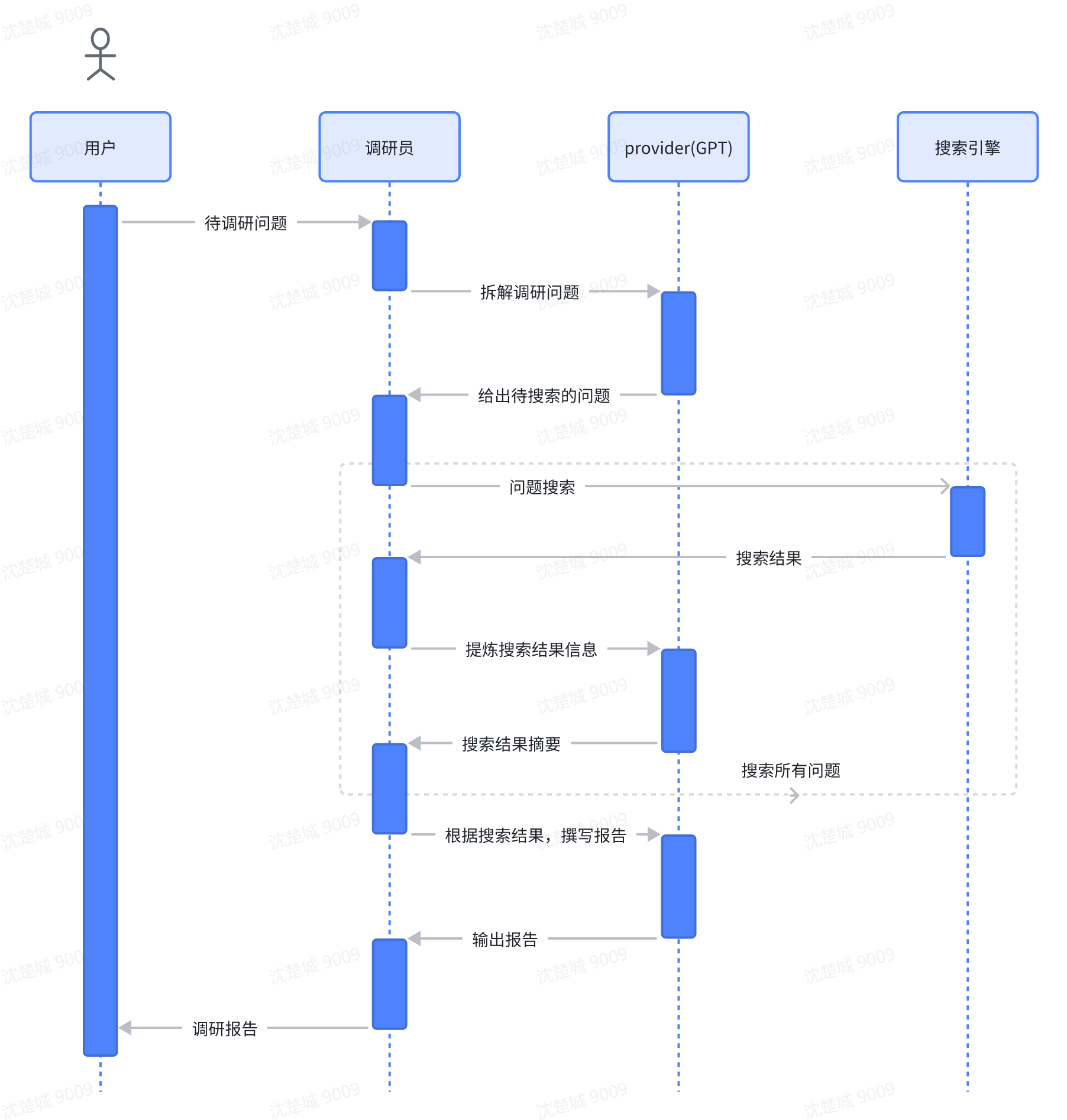
因此,我们尝试让GPT模拟以上的调研流程,整体步骤如下:
- 用户输入待调研问题
- 调研员通过GPT生成一组研究问题,这些问题共同形成对任何给定任务的客观意见
- 调研员在收到GPT分解的问题后,对于每个研究问题,先通过搜索引擎搜索,获取初次搜索结果
- 网址通过浏览器获取网页内容,并使用对网页内容进行总结
- 汇总所有总结后的内容并跟踪其来源
- 最后,让GPT根据汇总后的内容生成最终研究报告
以下是流程图:
针对以上的流程,我们可以抽象出3个Action,定义一个Role,如下:
| 名称 | 类型 | 说明 |
|---|---|---|
| CollectLinks | Action | 从搜索引擎进行搜索,并获取Url地址列表 |
| WebBrowseAndSummarize | Action | 浏览网页并总结网页内容 |
| ConductResearch | Action | 生成调研报告 |
| Researcher | Role | 调研员智能体,从网络进行搜索并总结报告 |
Action定义
CollectLinks
CollectLinks Action用于从搜索引擎搜索相关问题并获取Url地址列表。因为用户输入的问题不一定适合直接通过搜索引擎搜索,因此在进行搜索之前,先将用户输入的问题拆分成多个适合搜索的子问题,然后通过搜索引擎搜索这些子问题,筛选出与调研问题有关的Url,并根据网站可靠性对url列表进行排序。MetaGPT在tools中已经实现了SearchEngine,支持通过serpapi/google/serper/ddg进行网络搜索,CollectLinks使用SearchEngine进行网络搜索。具体的实现参考metagpt/actions/research.py的CollectLinks的定义,以下是对CollectLinks.run的基础说明:
class CollectLinks(Action):
async def run(
self,
topic: str,
decomposition_nums: int = 4,
url_per_query: int = 4,
system_text: str | None = None,
) -> dict[str, list[str]]:
"""从搜索引擎进行搜索,并获取Url地址信息。
Args:
topic: 待调研问题
decomposition_nums: 子问题拆解数
url_per_query: 每个子问题搜索的生成的Url数
system_text: 系统提示词
Returns:
搜索结果字典,键为子问题,值为Url列表
"""
system_text = system_text if system_text else RESEARCH_TOPIC_SYSTEM.format(topic=topic)
# 将待调研问题拆解成多个子问题
keywords = await self._aask(SEARCH_TOPIC_PROMPT, [system_text])
try:
keywords = OutputParser.extract_struct(keywords, list)
keywords = parse_obj_as(list[str], keywords)
except Exception as e:
logger.exception(f"fail to get keywords related to the research topic \"{topic}\" for {e}")
keywords = [topic]
# 用搜索引擎对对子问题进行搜索
results = await asyncio.gather(*(self.search_engine.run(i, as_string=False) for i in keywords))
# 浏览搜索引擎给出的结果,并筛选出与待调研的问题相关的搜索结果
def gen_msg():
while True:
search_results = "\n".join(f"#### Keyword: {i}\n Search Result: {j}\n" for (i, j) in zip(keywords, results))
prompt = SUMMARIZE_SEARCH_PROMPT.format(decomposition_nums=decomposition_nums, search_results=search_results)
yield prompt
remove = max(results, key=len)
remove.pop()
if len(remove) == 0:
break
prompt = reduce_message_length(gen_msg(), self.llm.model, system_text, CONFIG.max_tokens_rsp)
logger.debug(prompt)
queries = await self._aask(prompt, [system_text])
try:
queries = OutputParser.extract_struct(queries, list)
queries = parse_obj_as(list[str], queries)
except Exception as e:
logger.exception(f"fail to break down the research question due to {e}")
queries = keywords
ret = {}
# 对搜索结果的Url进行排序,并取TopK
for query in queries:
ret[query] = await self._search_and_rank_urls(topic, query, url_per_query)
return retclass CollectLinks(Action):
async def run(
self,
topic: str,
decomposition_nums: int = 4,
url_per_query: int = 4,
system_text: str | None = None,
) -> dict[str, list[str]]:
"""从搜索引擎进行搜索,并获取Url地址信息。
Args:
topic: 待调研问题
decomposition_nums: 子问题拆解数
url_per_query: 每个子问题搜索的生成的Url数
system_text: 系统提示词
Returns:
搜索结果字典,键为子问题,值为Url列表
"""
system_text = system_text if system_text else RESEARCH_TOPIC_SYSTEM.format(topic=topic)
# 将待调研问题拆解成多个子问题
keywords = await self._aask(SEARCH_TOPIC_PROMPT, [system_text])
try:
keywords = OutputParser.extract_struct(keywords, list)
keywords = parse_obj_as(list[str], keywords)
except Exception as e:
logger.exception(f"fail to get keywords related to the research topic \"{topic}\" for {e}")
keywords = [topic]
# 用搜索引擎对对子问题进行搜索
results = await asyncio.gather(*(self.search_engine.run(i, as_string=False) for i in keywords))
# 浏览搜索引擎给出的结果,并筛选出与待调研的问题相关的搜索结果
def gen_msg():
while True:
search_results = "\n".join(f"#### Keyword: {i}\n Search Result: {j}\n" for (i, j) in zip(keywords, results))
prompt = SUMMARIZE_SEARCH_PROMPT.format(decomposition_nums=decomposition_nums, search_results=search_results)
yield prompt
remove = max(results, key=len)
remove.pop()
if len(remove) == 0:
break
prompt = reduce_message_length(gen_msg(), self.llm.model, system_text, CONFIG.max_tokens_rsp)
logger.debug(prompt)
queries = await self._aask(prompt, [system_text])
try:
queries = OutputParser.extract_struct(queries, list)
queries = parse_obj_as(list[str], queries)
except Exception as e:
logger.exception(f"fail to break down the research question due to {e}")
queries = keywords
ret = {}
# 对搜索结果的Url进行排序,并取TopK
for query in queries:
ret[query] = await self._search_and_rank_urls(topic, query, url_per_query)
return retWebBrowseAndSummarize
WebBrowseAndSummarize Action用于浏览网页并总结网页内容。MetaGPT在tools中已经实现了WebBrowserEngine,支持通过playwright/selenium进行网页浏览,WebBrowseAndSummarize使用WebBrowserEngine进行网页浏览。具体的实现参考metagpt/actions/research.py的WebBrowseAndSummarize的定义,以下是对WebBrowseAndSummarize.run的基础说明:
class WebBrowseAndSummarize(Action):
async def run(
self,
url: str,
*urls: str,
query: str,
system_text: str = RESEARCH_BASE_SYSTEM,
) -> dict[str, str]:
"""浏览网页并总结网页内容
Args:
url: 待浏览与总结的网页Url
urls: 其他的待浏览与总结的网页Url元组
query: 搜索的问题
system_text: 系统提示词
Returns:
总结的结果字典,键为Url,值为总结结果
"""
# 网页浏览与内容提取
contents = await self.web_browser_engine.run(url, *urls)
if not urls:
contents = [contents]
# 网页内容总结
summaries = {}
prompt_template = WEB_BROWSE_AND_SUMMARIZE_PROMPT.format(query=query, content="{}")
for u, content in zip([url, *urls], contents):
content = content.inner_text
chunk_summaries = []
for prompt in generate_prompt_chunk(content, prompt_template, self.llm.model, system_text, CONFIG.max_tokens_rsp):
logger.debug(prompt)
summary = await self._aask(prompt, [system_text])
if summary == "Not relevant.":
continue
chunk_summaries.append(summary)
if not chunk_summaries:
summaries[u] = None
continue
if len(chunk_summaries) == 1:
summaries[u] = chunk_summaries[0]
continue
content = "\n".join(chunk_summaries)
prompt = WEB_BROWSE_AND_SUMMARIZE_PROMPT.format(query=query, content=content)
summary = await self._aask(prompt, [system_text])
summaries[u] = summary
return summariesclass WebBrowseAndSummarize(Action):
async def run(
self,
url: str,
*urls: str,
query: str,
system_text: str = RESEARCH_BASE_SYSTEM,
) -> dict[str, str]:
"""浏览网页并总结网页内容
Args:
url: 待浏览与总结的网页Url
urls: 其他的待浏览与总结的网页Url元组
query: 搜索的问题
system_text: 系统提示词
Returns:
总结的结果字典,键为Url,值为总结结果
"""
# 网页浏览与内容提取
contents = await self.web_browser_engine.run(url, *urls)
if not urls:
contents = [contents]
# 网页内容总结
summaries = {}
prompt_template = WEB_BROWSE_AND_SUMMARIZE_PROMPT.format(query=query, content="{}")
for u, content in zip([url, *urls], contents):
content = content.inner_text
chunk_summaries = []
for prompt in generate_prompt_chunk(content, prompt_template, self.llm.model, system_text, CONFIG.max_tokens_rsp):
logger.debug(prompt)
summary = await self._aask(prompt, [system_text])
if summary == "Not relevant.":
continue
chunk_summaries.append(summary)
if not chunk_summaries:
summaries[u] = None
continue
if len(chunk_summaries) == 1:
summaries[u] = chunk_summaries[0]
continue
content = "\n".join(chunk_summaries)
prompt = WEB_BROWSE_AND_SUMMARIZE_PROMPT.format(query=query, content=content)
summary = await self._aask(prompt, [system_text])
summaries[u] = summary
return summariesConductResearch
ConductResearch Action用于撰写调研报告。它的实现较为简单,将ConductResearch总结后的资料作为上下文,然后撰写调研报告。具体的实现参考metagpt/actions/research.py的ConductResearch的定义,以下是对ConductResearch.run的基础说明:
class ConductResearch(Action):
async def run(
self,
topic: str,
content: str,
system_text: str = RESEARCH_BASE_SYSTEM,
) -> str:
"""撰写调研报告
Args:
topic: 调研主题
content: 参考资料
system_text: 系统提示词
Returns:
调研报告内容
"""
prompt = CONDUCT_RESEARCH_PROMPT.format(topic=topic, content=content)
logger.debug(prompt)
self.llm.auto_max_tokens = True
return await self._aask(prompt, [system_text])class ConductResearch(Action):
async def run(
self,
topic: str,
content: str,
system_text: str = RESEARCH_BASE_SYSTEM,
) -> str:
"""撰写调研报告
Args:
topic: 调研主题
content: 参考资料
system_text: 系统提示词
Returns:
调研报告内容
"""
prompt = CONDUCT_RESEARCH_PROMPT.format(topic=topic, content=content)
logger.debug(prompt)
self.llm.auto_max_tokens = True
return await self._aask(prompt, [system_text])Role(Researcher)
Researcher通过组合CollectLinks、WebBrowseAndSummarize、ConductResearch三个Action,实现从网络进行搜索并总结报告的能力。因此,上述三个Action需要在Researcher初始化时,通过_init_actions方法,添加到角色中。这三个Action中,是按照CollectLinks->WebBrowseAndSummarize->ConductResearch顺序执行的,所以需要在react/_act定义这三个Action的执行逻辑。具体的实现参考metagpt/roles/researcher.py的Researcher的定义,以下是对Researcher的基础说明:
class Researcher(Role):
def __init__(
self,
name: str = "David",
profile: str = "Researcher",
goal: str = "Gather information and conduct research",
constraints: str = "Ensure accuracy and relevance of information",
language: str = "en-us",
**kwargs,
):
super().__init__(name, profile, goal, constraints, **kwargs)
# 添加`CollectLinks`、`WebBrowseAndSummarize`、`ConductResearch`三个Action
self._init_actions([CollectLinks(name), WebBrowseAndSummarize(name), ConductResearch(name)])
# 设置为顺序执行
self._set_react_mode(react_mode="by_order")
self.language = language
if language not in ("en-us", "zh-cn"):
logger.warning(f"The language `{language}` has not been tested, it may not work.")
async def _act(self) -> Message:
logger.info(f"{self._setting}: ready to {self._rc.todo}")
todo = self._rc.todo
msg = self._rc.memory.get(k=1)[0]
if isinstance(msg.instruct_content, Report):
instruct_content = msg.instruct_content
topic = instruct_content.topic
else:
topic = msg.content
research_system_text = get_research_system_text(topic, self.language)
# 从搜索引擎进行搜索,并获取Url地址列表
if isinstance(todo, CollectLinks):
links = await todo.run(topic, 4, 4)
ret = Message("", Report(topic=topic, links=links), role=self.profile, cause_by=todo)
# 浏览网页并总结网页内容
elif isinstance(todo, WebBrowseAndSummarize):
links = instruct_content.links
todos = (todo.run(*url, query=query, system_text=research_system_text) for (query, url) in links.items())
summaries = await asyncio.gather(*todos)
summaries = list((url, summary) for i in summaries for (url, summary) in i.items() if summary)
ret = Message("", Report(topic=topic, summaries=summaries), role=self.profile, cause_by=todo)
# 生成调研报告
else:
summaries = instruct_content.summaries
summary_text = "\n---\n".join(f"url: {url}\nsummary: {summary}" for (url, summary) in summaries)
content = await self._rc.todo.run(topic, summary_text, system_text=research_system_text)
ret = Message("", Report(topic=topic, content=content), role=self.profile, cause_by=type(self._rc.todo))
self._rc.memory.add(ret)
return ret
async def react(self) -> Message:
msg = await super().react()
report = msg.instruct_content
# 输出报告
self.write_report(report.topic, report.content)
return msgclass Researcher(Role):
def __init__(
self,
name: str = "David",
profile: str = "Researcher",
goal: str = "Gather information and conduct research",
constraints: str = "Ensure accuracy and relevance of information",
language: str = "en-us",
**kwargs,
):
super().__init__(name, profile, goal, constraints, **kwargs)
# 添加`CollectLinks`、`WebBrowseAndSummarize`、`ConductResearch`三个Action
self._init_actions([CollectLinks(name), WebBrowseAndSummarize(name), ConductResearch(name)])
# 设置为顺序执行
self._set_react_mode(react_mode="by_order")
self.language = language
if language not in ("en-us", "zh-cn"):
logger.warning(f"The language `{language}` has not been tested, it may not work.")
async def _act(self) -> Message:
logger.info(f"{self._setting}: ready to {self._rc.todo}")
todo = self._rc.todo
msg = self._rc.memory.get(k=1)[0]
if isinstance(msg.instruct_content, Report):
instruct_content = msg.instruct_content
topic = instruct_content.topic
else:
topic = msg.content
research_system_text = get_research_system_text(topic, self.language)
# 从搜索引擎进行搜索,并获取Url地址列表
if isinstance(todo, CollectLinks):
links = await todo.run(topic, 4, 4)
ret = Message("", Report(topic=topic, links=links), role=self.profile, cause_by=todo)
# 浏览网页并总结网页内容
elif isinstance(todo, WebBrowseAndSummarize):
links = instruct_content.links
todos = (todo.run(*url, query=query, system_text=research_system_text) for (query, url) in links.items())
summaries = await asyncio.gather(*todos)
summaries = list((url, summary) for i in summaries for (url, summary) in i.items() if summary)
ret = Message("", Report(topic=topic, summaries=summaries), role=self.profile, cause_by=todo)
# 生成调研报告
else:
summaries = instruct_content.summaries
summary_text = "\n---\n".join(f"url: {url}\nsummary: {summary}" for (url, summary) in summaries)
content = await self._rc.todo.run(topic, summary_text, system_text=research_system_text)
ret = Message("", Report(topic=topic, content=content), role=self.profile, cause_by=type(self._rc.todo))
self._rc.memory.add(ret)
return ret
async def react(self) -> Message:
msg = await super().react()
report = msg.instruct_content
# 输出报告
self.write_report(report.topic, report.content)
return msg使用说明
依赖与配置
Researcher依赖了SearchEngine与WebBrowserEngine,以下针对二者的安装与配置作简单说明。
SearchEngine支持serpapi/google/serper/ddg等搜索引擎,它们区别如下:
| 名称 | 默认引擎 | 额外依赖包 | 安装 |
|---|---|---|---|
| serpapi | √ | \ | \ |
| × | google-api-python-client | pip install metagpt[search-google] | |
| serper | × | \ | \ |
| ddg | × | duckduckgo-search | pip install metagpt[search-ddg] |
配置:
- serpapi
- SEARCH_ENGINE: 设置为serpapi
- SERPAPI_API_KEY: 从https://serpapi.com/获取
- SEARCH_ENGINE: 设置为google
- GOOGLE_API_KEY: 从https://console.cloud.google.com/apis/credentials获取
- GOOGLE_CSE_ID: 从https://programmablesearchengine.google.com/controlpanel/create获取
- serper
- SEARCH_ENGINE: 设置为serper
- SERPER_API_KEY: 从https://serper.dev/获取
- ddg
- SEARCH_ENGINE: 设置为ddg
WebBrowserEngine支持playwright/selenium引擎,要使用它们都需要安装额外的依赖,它们区别如下:
| 名称 | 默认引擎 | 额外依赖包 | 安装 | 异步方式 | 支持的平台 |
|---|---|---|---|---|---|
| playwright | √ | playwright beautifulsoup4 | pip install metagpt[playwright] | 原生 | 支持部分平台 |
| selenium | × | selenium webdriver_manager beautifulsoup4 | pip install metagpt[selenium] | 线程池 | 几乎支持所有平台 |
配置:
- playwright
- WEB_BROWSER_ENGINE: 设置为playwright
- PLAYWRIGHT_BROWSER_TYPE: 支持chromium/firefox/webkit,默认chromium,更多信息参考https://playwright.dev/python/docs/api/class-browsertype
- selenium
- WEB_BROWSER_ENGINE: 设置为selenium
- SELENIUM_BROWSER_TYPE: 支持chrome/firefox/edge/ie, 默认chrome,更多信息参考https://www.selenium.dev/documentation/webdriver/browsers/
此外,Researcher本身也提供了以下两个配置:
- MODEL_FOR_RESEARCHER_SUMMARY: 用于内容总结的gpt模型,默认gpt-3.5-turbo
- MODEL_FOR_RESEARCHER_REPORT: 用于生成报告的gpt模型,默认gpt-3.5-turbo-16k
运行示例与结果
metagpt.roles.researcher提供了命令行用于执行Researcher的功能,示例如下:
python3 -m metagpt.roles.researcher "dataiku vs. datarobot"python3 -m metagpt.roles.researcher "dataiku vs. datarobot"输出日志:log.txt 输出报告: dataiku vs. datarobot.md